
答:此题邀请xinghua来解答,他总结了实际项目中对elk系统的一些调优的经验,与你分享百亿级elk日志系统优化纪实。
导语:elk是搭建实时日志分析系统的通用解决方案,通过elk可以方便地收集、搜索日志。但随着日志量的增加,根据实际应用场景的优化调整能够更充分的利用系统资源。本文主要记录我们项目中对elk系统的一些调优。
随着王者人生相关业务的快速发展,我们每天日志量很快超过了20亿条,存储超过2TB,elk日志系统的压力逐渐增加,日志系统的调整优化已经迫在眉睫。
1、日志系统架构
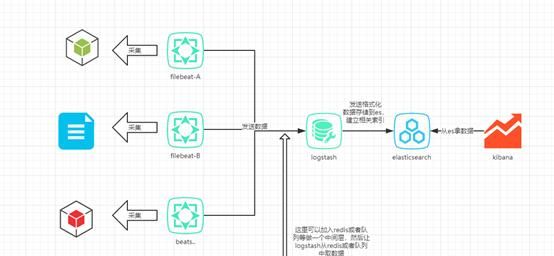

(elk日志系统架构)
FileBeat 是一个轻量级的日志收集处理工具(Agent)。
Elasticsearch 是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。
Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。
Kibana 可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
2、优化日志系统
以下主要介绍 filebeat、logstash、elasticsearch 的一些优化调整
2.1 filebeat优化
(1) 负载均衡
问题 :当日志量非常大(单机超过每天超100GB)的模块上报日志时,日志落地延时大,要等一段时间才能在es里查出来。
原因:
当filebeat.yml 配置文件里hosts配置了多个Logstash主机,并且loadbalance设置为true,则输出插件会将已发布的事件负载平衡到所有Logstash主机上。 如果设置为false,则输出插件仅将所有事件发送到一个主机(随机确定),如果所选主机无响应,则会切换到另一个主机。 默认值为false。
方案:配置多个hosts,配置loadbalance为true


(修改配置前只有一个连接)
 (负载均衡优化后多个连接)
(负载均衡优化后多个连接)
效果
单机filebeat吞吐量变大
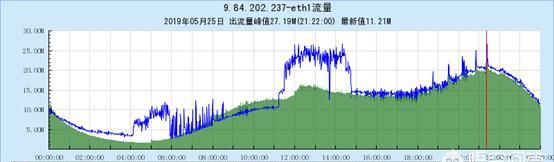
(多连接优化后单机出流量变大)
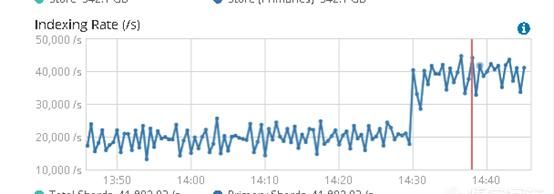
(es创建索引的速度变大)
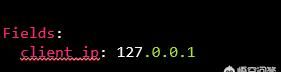
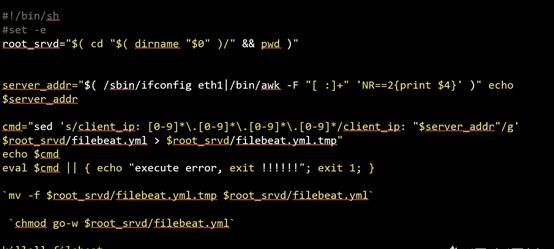
(2)上报采集 源服务器ip
问题:不是所有日志都会打印本机IP,比如异常错误日志往往无法打印服务器IP。这部分日志收集之后无法区分来源,难以定位问题。
原因:filebeat目前不支持上报本机ip
方案:添加字段client_ip,重启脚本动态修改client_ip为本机IP
filebeat.yml 部分配置
restart_filebeat.sh示例
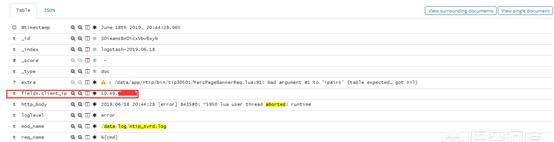
效果
异常日志也能定位服务器IP
2.2logstash优化
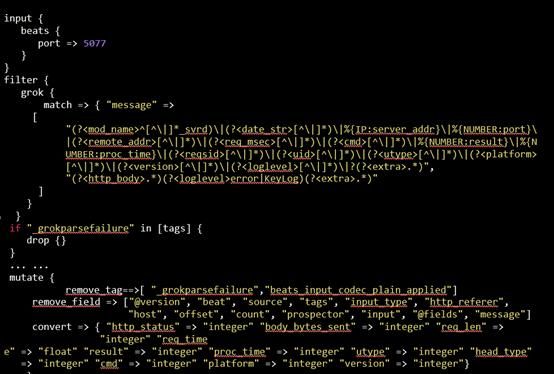
(1)日志清洗、格式化
问题:采集的原始日志不规范,需要过滤,格式化
方案:利用logstash进行清理
logstash.conf 示例
效果
以删掉message字段为例看效果
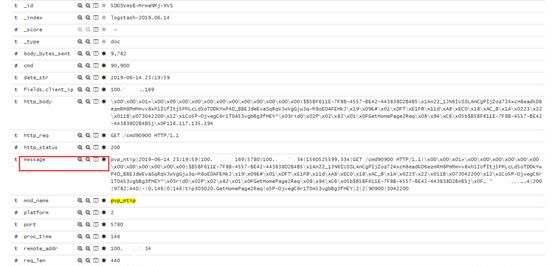
(删掉message前冗余一份完整原始日志)
效果
平均每条日志存储空间从1.2KB 下降到 0.84KB,减少了近30%的存储

(每天日志统计)
2.3elasticsearch优化
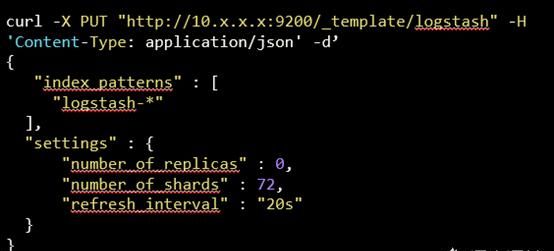
(1)优化模板_template配置
问题:随着王者荣耀wifi特权上线,日志量激增,默认配置下磁盘达到瓶颈。
原因:默认配置满足不了项目需要
number_of_shards 是数据分片数,默认为5
当es集群节点超过分片数时,不能充分利用所有节点
number_of_replicas 是数据备份数,默认是1
方案:调整模板配置
number_of_shards改为72
number_of_replicas改为0
效果
每天日志的72个分片均匀分部在36个节点

(每个节点分配了2个分片)
备份从 1 改成了 0,减少了一半的写入
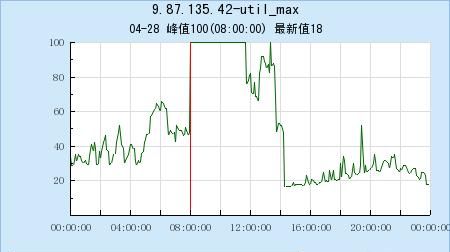
(io使用率降低)
3.总结
通过以上调整,目前elk日志系统可以支持每天超过20亿条,2.2 TB的日志,峰值创建索引超6万QPS
后续优化:不同配置(磁盘空间)机器按权重分配,充分利用资源
本文来自投稿,不代表天一生活立场,如若转载,请注明出处:http://tiyigo.com/baike/4150.html