
冒泡排序是一种复杂度为O(n2)的低效排序算法。它通过不断比较元素并交换位置使一个元素到达有序集合的正确位置上。
冒泡排序的过程是把相邻的数据元素进行交换,从而逐步将待排序序列变成有序序列。冒泡排序的基本思想是:从头扫描待排序序列,在扫描的过程中顺次比较相邻两个元素的大小。
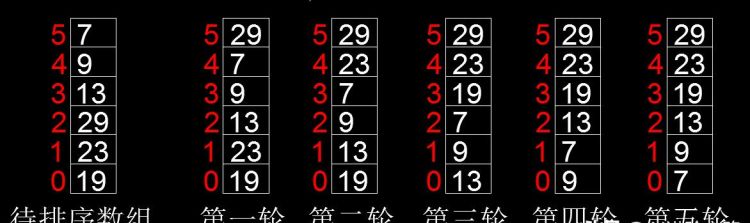
下面以升序为例介绍排序过程。
(1)在第一轮排序中,对n个记录进行如下操作。
①对相邻的两个记录的关键字进行比较,逆序时就交换位置。
②在扫描的过程中,不断向后移动相邻两个记录中关键字较大的记录。
③将待排序记录序列中的最大关键字记录交换到待排序记录序列的末尾,这也是最大关键字记录应在的位置。
(2)进行第二轮冒泡排序,对前n-1个记录进行同样的操作,其结果是使次大的记录被放在第n-2个记录的位置上。
(3)继续进行排序工作,在后面几轮的升序处理也反复遵循了上述过程,直到排好顺序为止。如果在某一轮冒泡过程中没有发现一个逆序,就可以马上结束冒泡排序。整个冒泡过程最多可以进行n-1轮,如图演示了一个完整的冒泡排序过程。
使用C语言实现冒泡排序的算法代码如下所示:
/*对数组 r 做冒泡排序,length为数组的长度*/
typedef int KeyType;
typedef struct {
KeyType key;
} RecordType ;
void BubbleSort(RecordType r[], int length ){
n=length;
change=TRUE;
for ( i=1 ; i<= n-1 && change ;++i ) {
change=FALSE;
for ( j=1 ; j<= n-i ; ++j)
if (r[j].key> r[j+1].key ) {
x= r[j];
r[j]= r[j+1];
r[j+1]= x;
change=TRUE;
}
}
} /* BubbleSort */

冒泡排序是排序算法中较为简单的一种,英文称为Bubble Sort。它遍历所有的数据,每次对相邻元素进行两两比较,如果顺序和预先规定的顺序不一致,则进行位置交换;这样一次遍历会将最大或最小的数据上浮到顶端,之后再重复同样的操作,直到所有的数据有序。
如果有n个数据,那么需要的比较次数,所以当数据量很大时,冒泡算法的效率并不高。
当输入的数据是反序时,花的时间最长,当输入的数据是正序时,时间最短。
平均时间复杂度:
空间复杂度:O(1)
#include “stdio.h”
void swap(int *t1, int *t2)
{
int temp;
temp = *t1;
*t1 = *t2;
*t2 = temp;
}
void bubble_sort(int arr[], int len)
{
int i, j;
for (i = 0; i < len -1; i++) {
for (j = 0; j < len -1 -i; j++) {
if (arr[j] > arr[j + 1]) {
swap(&arr[j], &arr[j + 1]);
}
}
}
}
int main()
{
int arr[] = {34, 27, 55, 8, 97, 67, 35, 43, 22, 101, 78, 96, 35, 99};
int i;
int len = sizeof(arr) / sizeof(*arr);
bubble_sort(arr, len);
printf(“len = %d n”, len);
printf(“use bubble sort the arrary is: “);
for(i = 0; i < len; i++){
printf(“%d “, arr[i]);
}
printf(“n”);
}
———————————————— 河南新华
本文来自投稿,不代表天一生活立场,如若转载,请注明出处:http://tiyigo.com/it/15119.html