
个人接触过ElementTree,就简单介绍一下这个包。ElementTree是python中常用处理xml文件的类。
引用方法
import xml.etree.ElementTree as ET
解析XML
-
读取xml
import xml.etree.ElementTree as ET
tree = ET.parse(filename)
root = tree.getroot()
root = ET.fromstring(string)
-
查看tag和attribute
root.tag
root.attrib
for child in root:
print child.tag,child.attrib
-
使用下标访问
root[i].tag
-
使用tag名称访问
Element.iter()
Element.findall()
Element.find()


支持xpath,xpath是xml语言中语法结构, 解析起来就更加直观化。
这里介绍2种python解析xml文件的方式,一种基于SAX事件驱动的方式,一种基于DOM树的方式,下面我大概介绍一下过程,实验环境win10+python3.6+pycharm5.0,主要内容如下:
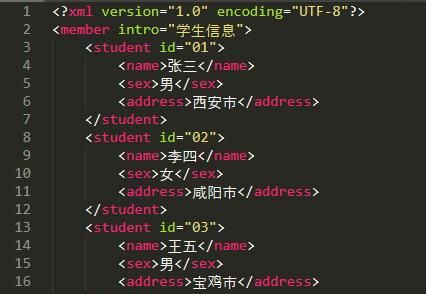
为了会更好的说明问题,这里我新建了一个test.xml文件,主要内容如下,很简单:
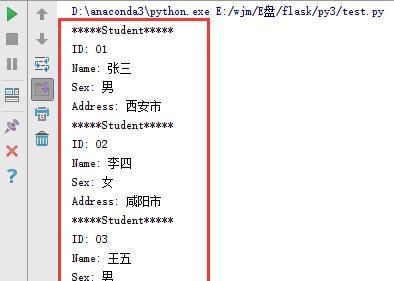
1.SAX解析xml:SAX是一种快速的解析xml文件方式,在解析xml文件时,不会占用大量内存,通过触发一个个事件来调用用户的回调函数处理xml文件,测试代码如下,主要是继承ContentHandler类,并对startElement,endElement,characters这3个方法重写:

程序运行截图如下,已经成功解析出xml文件信息:
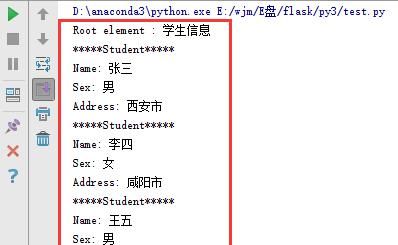
2.DOM解析xml文件:这种方式比较简单,好理解,在内存中将xml文件解析成一个树,通过对树的解析来操作xml文件,缺点是占用内存,速度慢,测试代码如下,按着xml文件结构解析就行:

程序运行截图如下,已经成功解析出xml文件:
至此,我们就完成了利用python来解析xml文件。总的来说,整个过程很简单,就是基于SAX和DOM这2种方式,只要你有一定的python基础,多加练习,很快就能掌握的,网上也有相关资料和教程,感兴趣的可以搜一下,希望以上分享的内容能对你有所帮助吧。
本文来自投稿,不代表天一生活立场,如若转载,请注明出处:http://tiyigo.com/it/17534.html